2026年7月8日Evgeny · 高级系统工程师
生产环境监控:普通人也能看懂的 4 个指标
客户说「付不了款」。您打开网站——首页正常。一小时后才发现支付按钮的后端挂了,广告费却在烧。
这是典型的 production(正式环境)事故。下面四个指标老板和运营都能懂,并覆盖常见搜索词:production 监控、服务器指标、DevOps、Grafana。

为什么「服务器能 ping」不够
主机商显示 99.9% 可用,但结账报错、响应 8 秒、服务器即将满载——首页检查都看不到。
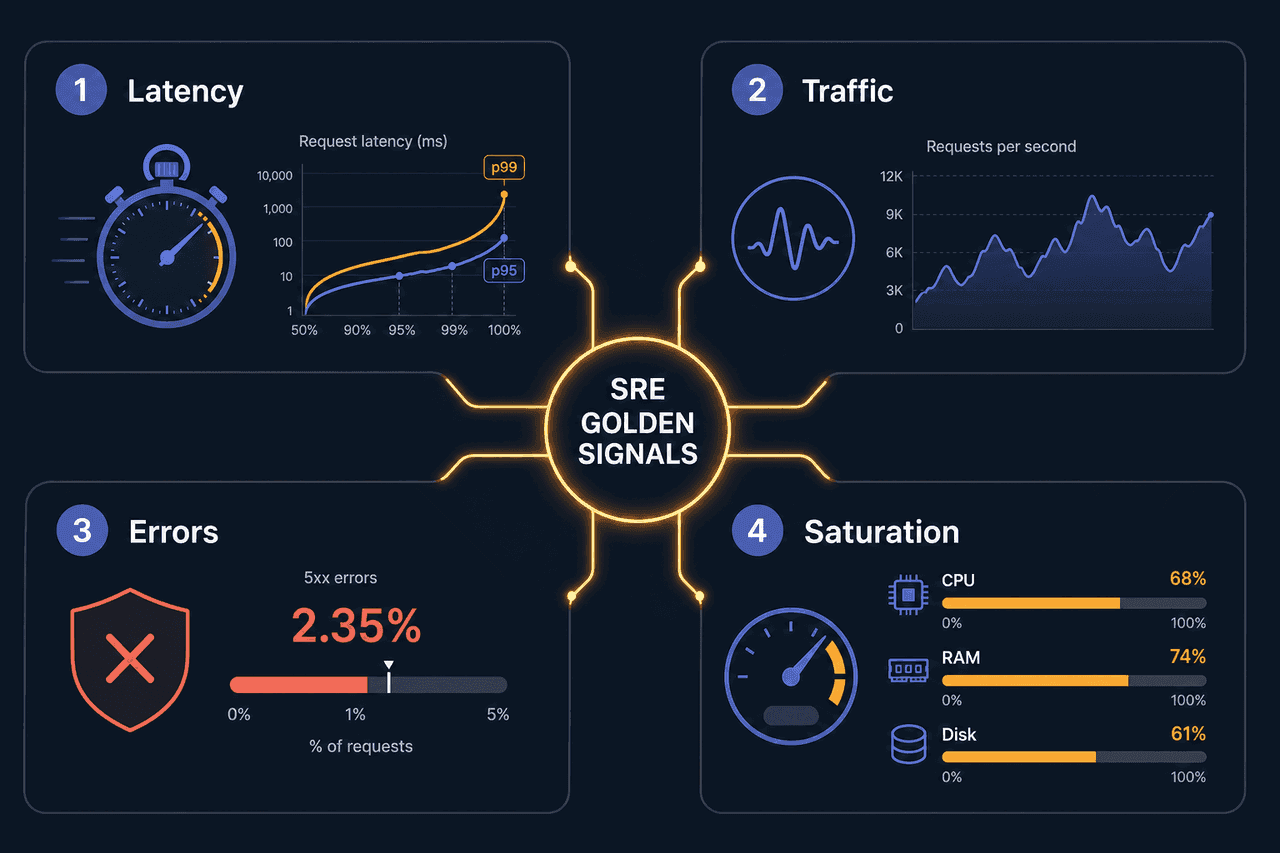
4 个关键指标

- 响应速度 — 点击后等多久;多数人超过 2–3 秒就会流失
- 流量与负载 — 半小时内 3–5 倍尖峰可能是广告或攻击
- 错误 — 即使 0.5% 在高流量下也是每分钟大量失败
- 服务器余量 — CPU/内存持续 70–80% 就该预警,别等 99%
问 IT 或供应商的 5 个问题
- 支付挂了谁第一个知道——自动告警还是客户投诉?
- 承诺多快的响应?(如 99% 请求 < 1 秒)
- 每月允许多少宕机?(99.9% ≈ 每月 43 分钟)
- 大促当天谁值班?
- 投广前是否做了压测?
总结
Production 监控是在客户来电之前发现问题,通常属于 DevOps 服务。参见停机成本。
网站监控常见问题
只检查首页看不到购物车或支付接口故障。要监控客户真实操作——下单、登录、付款。
三个告警:网站不可用、错误激增、响应超过 2–3 秒。Telegram 通知即可起步。
不必。先简单告警和一块清晰看板;流量和团队变大再上新工具。
DevOps 不仅发布代码,还包括 production 可观测性:指标、告警、峰值容量。
相关文章
DevOps / SRE2026年6月19日
生产环境 DevOps 与 CI/CD:应优先配置什么
面向业务的 DevOps 服务:构建流水线、Staging、零停机部署、 监控与回滚 — 前 4–6 周的优先级。
阅读文章DevOps / SRE2026年6月19日
生产环境 Kubernetes:集群上线前 CTO 检查清单
生产级 Kubernetes 配置:RBAC、资源配额、Ingress、GitOps、监控 与常见错误 — 上线前的检查清单。
阅读文章DevOps / SRE2026年1月5日
为什么企业需要 SRE?将可靠性转化为金钱
企业为何需要 SRE:SLI、SLO、错误预算与“可靠性=成本”的视角,在不过度追求虚荣可用性的前提下平衡发布速度。
阅读文章DevOps / SRE2025年12月10日
CI/CD:如何不再害怕周五发布
面向业务结果的 CI/CD:手动发布为何比宕机更贵、流水线如何降低发布风险,以及从代码仓库到生产环境应优先自动化的环节。
阅读文章